Unsupervised Speech Disentanglement
Unsupervised Speech Disentanglement
Speech Processing Lab supervised by Prof. Hung-Yi Lee
Speech Processing Lab
supervised by Prof. Hung-Yi Lee
Implement voice conversion framework with disentanglement analysis.
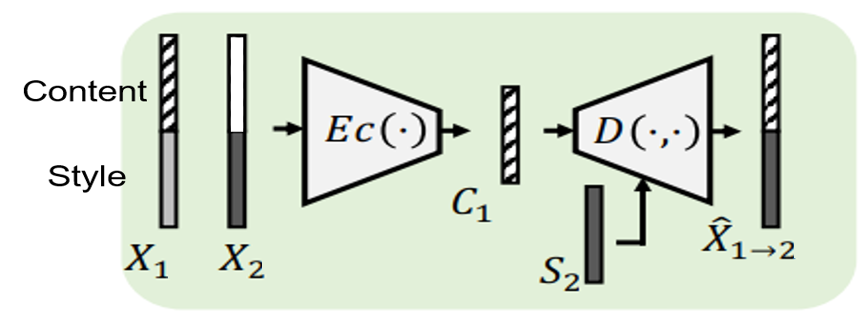
Figure 1. Sample speech generated by our disentangled framework.
Recently, voice conversion (VC) without parallel data has been successfully adapted to multi-target scenario. However, such model suffers from the limitation that it can only convert the voice to the speakers in the training data. In this research, we aim to develop speech disentanglement for zero-shot voice conversion. Speech can be disentangled into speaker and content representation with instance normalization (IN) technique which we can extract unique mean and standard deviation value as speaker information. We implemet our VC framework with Variational Autoencoder (VAE) and conversion samples are shown above on Figure 1.
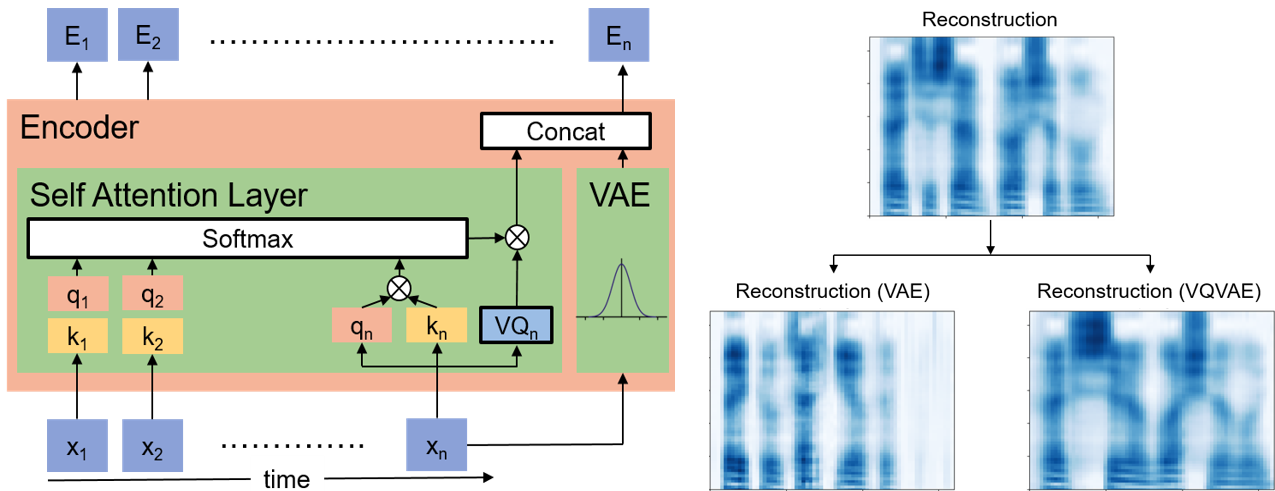
Figure 2. Continuous and discrete speech disentanglement.
Besides speaker information, the content part includes phoneme and prosody information which can be viewed as discrete and continuous representation repectively. Therefore, we modified the content encoder with quantized self-attention layer and VAE, as shown above on Figure 2. However, even if we can easily distinguish the spectrogram between discrete and continuous representation, it is still hard to define their meanings.
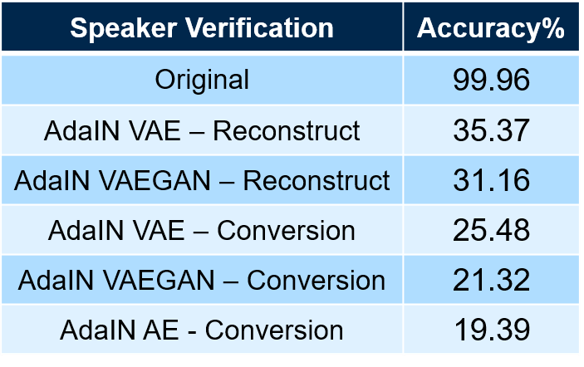
Figure 3. Speaker sproofing as a benchmark for zero-shot voice conversion.
To evaluate our zero-shot voice conversion framework, we implment speaker sproofing on unseen dataset as our benchmark, which we want our conversion samples can cheat the verification classifier. It is obvious that the reconstruct samples show there is still a gap between datasets. In order to develop a general framework for real world applications, we still have lots of works to research on speech disentanglement for zero-shot voice conversion. For more information, our code is publically available on GitHub.