Text to Speech without Text
Team Project @ CSIE5431 Applied Deep Learning
Team Project @ CSIE5431
Applied Deep Learning
Compare MBV and VQVAE
for discrete representations of subword units
in the ZeroSpeech 2019 Challenge.
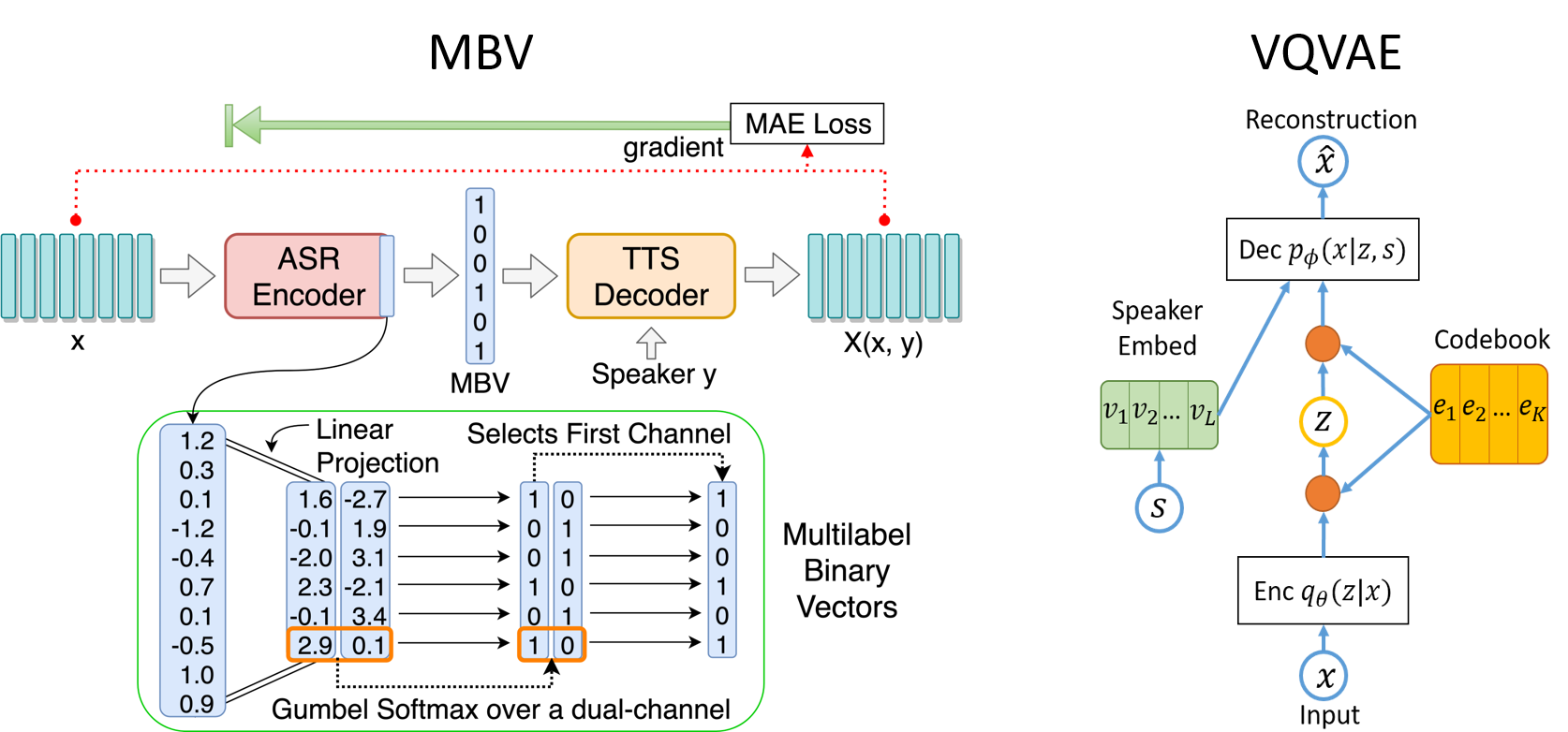
Figure 1. MBV and VQVAE model architecture.
The underlying training methods on text to speech usually require the large quantity of labeled training data, including text labels or phoneme labels. However, it is quiet challenging and costly to collect high-quality parallel corpora for the low-resourced languages. In this project, we compare the Multilabel-Binary Vectors (MBV) autoencoder and the Vector Quantized Variational Autoencoder (VQVAE). These two methods share a similar autoencoder backbone while trying to discretize the continuous output of the encoder in a different manner, which are listed above in Figure 1.
| Source | Continuous | ||
| MBV | MBV-ADV | ||
| VQVAEv1 | VQVAEv2 |
| Source | |
| Continuous | |
| MBV | |
| MBV-ADV | |
| VQVAEv1 | |
| VQVAEv2 |
Figure 2. Speech samples for voice conversion.
In order to improve the performances and explore the trade-offs, we introduced different techniques including adversarial learning and vector quantized. For the evaluation, we first compare same-speaker reconstruction in training loss, spectrogram, and voice sample. After that, we generate speech as voice conversion task and compare in terms of bitrate and quality which is shown above in Figure 2. For more information, please refer to our report.